本文介绍了python中异步的概念以及如何使用异步来完成任务,部分概念与介绍并非官方准确的定义,为个人理解。如需更加原始与详细的说明请查看参考文献中的链接。
本文分为了以下几部分:异步概念的介绍,异步的使用规则,异步与生成器的联系,使用异步库编写一个完整的程序,零碎的小知识。文中不包含异步具体的实现方式。
文中部分示例代码可以在这个库中找到 https://github.com/realpython/materials/tree/master/asyncio-walkthrough
python版本3.7以上
需要pip包:aiohttp aiofiles
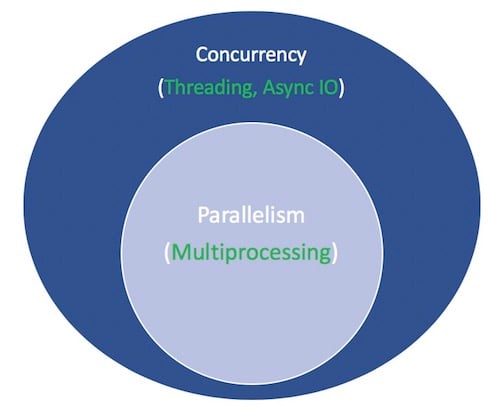
并发:同一时间多次调用同一接口,相应的接口程序可以同时处理这些调用,也可以依次处理
并行:多个操作同时运行,可以使用多线程,也可以使用多进程
进程:单个程序运行的过程
线程:一个进程可以有若干个线程,这些线程共享同一进程的某些数据
并发并不意味着必须要使用并行技术,因为在接受到并发的的调用之后,所有的任务可以依次处理。但是并行技术可以提升并发的处理能力。
python程序的多线程并不是真正的多线程,因为GIL
一张说明并发与并行的图
异步可以理解为一种中断机制:在将要执行异步代码时候,程序会把控制权移交给调用该函数的上一级然后告诉上一级等我执行完这部分程序给你发信号之后就把控制权还回来,之后便执行异步代码,在异步代码结束后发信号索要控制权。
举个例子:有两个人A和B同时在准备晚饭,但是这两个人只有一把菜刀,这个时候A和B叫来了C帮忙在中间传递菜刀。A的做菜顺序是 切菜→ 焯水→ 再切一遍 → 炒菜,B的做菜顺序是 洗菜 → 切菜 → 炒菜,如图所示:
例子中的菜刀就是异步中的程序控制权,图中的橙色线和网格块就是控制权的移交步骤,首先A拿到菜刀,也就是控制权,开始处理程序。等A处理完了切菜的步骤之后把菜刀给C,并且要在下一次切菜的时候再要回来,然后A开始处理焯水程序。这个时候B处理完了洗菜程序,向C索要控制权进行切菜,在处理完切菜程序之后进行和A一样的操作。在A处理完焯水步骤之后就索要控制权,如果控制权正好空闲那么A可以拿到,如果此时B没有归还那么A需要进行等待。C在整个过程中就在不停的问A和B菜刀还在用吗?需要菜刀吗?在A和B需要菜刀和不需要的时候将菜刀拿到自己的手上以便于下一次的传递。
例子中A和B就是两个需要控制权的协程,而C就是系统,来控制不同的协程完成工作。
异步的问题完全可以由多线程或者多进程来完成,那为什么还要引入异步操作呢?
异步操作比多线程与多进程更加的轻量化即相同数目的操作需要的资源更少
因为轻量化所以异步的并发数可以比多线程与多线程更多
异步的核心是协程 ,协程是python的生成器函数的一种特例。使用异步语法运行的函数就会创建一个协程,协程可以在运行到return语句之前挂起(意味着把控制权转让给调用程序,但是协程还在运行),并且协程可以把系统的控制权转让给其他的协程。
首先是一个简单的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import asyncioasync def count (): print ("One" ) await asyncio.sleep(1 ) print ("Two" ) async def main (): await asyncio.gather(count(), count(), count) if __name__ == "__main__" : import time s = time.perf_counter() asyncio.run(main()) elapsed = time.perf_counter() - s print (f"{__file__} executed in {elapsed:0.2 f} seconds" )
运行程序,查看输出:
1 2 3 4 5 6 7 8 $ python3 countasync.py One One One Two Two Two countasync.py executed in 1.01 seconds.
一个类似的程序,但是是非异步版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import timedef count (): print ("One" ) time.sleep(1 ) print ("Two" ) def main (): for _ in range (3 ): count() if __name__ == "__main__" : s = time.perf_counter() main() elapsed = time.perf_count() - s print (f"{__file__} executed in {elapsed:0.2 f} seconds." }
运行程序,查看输出
1 2 3 4 5 6 7 8 $ python3 countsync.py One Two One Two One Two countsync.py executed in 3.01 seconds.
可以看出以同步方式来运行的程序时间为3s,而异步方式为1s。同步方式运行的程序中,在sleep的时候程序被阻塞住,不能够继续运行或者转移控制权只能整个程序等待sleep,而异步方式可以让其他的协程在等待的时候运行,节省了时间。
async def 可以用来定义一个协程或者一个异步生成器,async可以和async for同时使用,下面就有这样的例子。
关键字await会将控制权还给event loop
1 2 3 4 async def g (): r = await f() return r
如果async def来定义一个异步函数,await return 和yield都是可以再函数中使用的,async def noop(): pass 也是可以的
必须使用await来获取一个异步函数的结果
在async def定义的函数中可以使用yield关键字(只有新版本的python中可以)
async def定义的函数中不可以使用yield from
await不可以在非异步函数中使用
1 2 3 4 5 6 7 8 9 10 11 12 13 async def f (x ): y = await z(x) return y async def g (x ): yield x async def m (x ): yield from gen(x) def m (x ): y = await z(x) return y
当你使用await f()的时候,f()必须是可等待的(awaitable),有两种情况
f()是一个协程
f()是一个定义了__await__()方法的对象,并且这个函数返回了一个迭代对象
可以使用装饰器的方式来创建基于生成器的协程,不要过多的纠结于这样的使用方式,在python 3.10版本之后这样的使用方式就会被删除。
1 2 3 4 5 6 7 8 9 10 import asyncio@asyncio.coroutine def py34_coro (): yield from stuff() async def py35_coro (): await stuff()
在了解了异步IO的规则之后,再看一个例子,这个示例程序展示了如何使用异步方式来节省程序的运行时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import asyncioimport randomc = ( "\033[0m" , "\033[36m" , "\033[91m" , "\033[35m" , ) async def makerandom (idx:int , threshold:int = 6 )->int : print (c[idx + 1 ] + f"Inititaed makerandom ({idx} )." ) i = random.randint(0 , 10 ) while i <= threshold: print (c[idx + 1 ] + f"makerandom ({idx} ) == {i} too low; retrying." ) await asyncio.sleep(idx + 1 ) i = random.randint(0 , 10 ) print (c[idx + 1 ] + f"---->Finished: makerandom ({idx} ) == {i} " + c[0 ]) async def main (): res = await asyncio.gather(*(makerandom(i, 10 - i -1 ) for i in range (3 ))) return res if __name__ == "__main__" : random.seed(666 ) r1, r2, r3 = asyncio.run(main()) print () print (f"r1: {r1} r2:{r2} r3:{r3} " )
输出效果:
上面的代码中定义了一个异步函数,并且用这个函数创建了三个不同输入的协程,在实际的应用中输入可能是一个url的列表,这样异步操作就可以处理多个web请求。程序中获取随机数的部分可以看作为计算密集的操作,而sleep部分可以看作为IO密集的操作,采用异步可以在IO密集的操作部分节省大量的时间。
异步函数可以链式调用即可以在一个异步函数中多次调用不同的异步函数,这样可以将整个程序分割为若干部分,方便调用。
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import sayncioimport randomimport timeasync def part1 (n: int ) -> str : i = random.randint(0 , 10 ) print (f"part1 ({n} ) sleep for {i} seconds." ) await asyncio.sleep(i) result = f"result{n} - 1" print (f"Returning part1 ({1 } ) == {result} " ) return result async def part2 (n:int , arg:str )->str : i = random.randint(0 ,10 ) print (f"part2 {n,arg} sleeping for {i} seconds." ) await asyncio.sleep(i) result = f"result {n} -2 derived from {arg} " print (f"Returning part2 {n, arg} == {result} " ) return result async def chain (n:int )->None : start = time.perf_counter() p1 = await part1(n) p2 = await part2(n, p1) end = time.perf_counter() - start print (f"-->Chained result {n} => {p2} (took {end:0.5 f} seconds)." ) async def main (*args ): await asyncio.gather(*(chain(n) for n in args)) if __name__ == "__main__" : import sys random.seed(666 ) args = [1 , 2 , 3 ] if len (sys.argv) == 1 else map (int , sys.argv[1 :]) start = time.perf_counter() asyncio.run(main(*args)) end = time.perf_counter() - start print (f"Program finished in {end: 0.5 f} seconds." )
运行程序,查看输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ python3 chained.py 9 6 3 part1(9 ) sleeping for 4 seconds. part1(6 ) sleeping for 4 seconds. part1(3 ) sleeping for 0 seconds. Returning part1(3 ) == result3-1. part2(3 , 'result3-1' ) sleeping for 4 seconds. Returning part1(9 ) == result9-1. part2(9 , 'result9-1' ) sleeping for 7 seconds. Returning part1(6 ) == result6-1. part2(6 , 'result6-1' ) sleeping for 4 seconds. Returning part2(3 , 'result3-1' ) == result3-2 derived from result3-1. -->Chained result3 => result3-2 derived from result3-1 (took 4.00 seconds). Returning part2(6 , 'result6-1' ) == result6-2 derived from result6-1. -->Chained result6 => result6-2 derived from result6-1 (took 8.01 seconds). Returning part2(9 , 'result9-1' ) == result9-2 derived from result9-1. -->Chained result9 => result9-2 derived from result9-1 (took 11.01 seconds). Program finished in 11.01 seconds.
在asyncio库中提供了队列类,作用和普通的队列类似,不过它是异步的。此外异步中的队列是线程安全的,即可以同时访问队列数据而无需考虑数据安全。
举例一个场景:有若干的生产者和消费者,并且任意的消费者或者生产者没有相互关系,不需要相互协作,生产者只需要将产品放入队列,而消费值需要不停的拿取产品处理。
对于同步处理的程序,需要让所有的消费者等待生产者的生产,在所有的生产者完成任务之后,消费者们依次取下产品处理,整个过程十分耗时。当然也可以通过多线程的方式,有若干线程来完成生产和消费的动作。
使用异步程序处理,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import asyncioimport randomimport itertools as itimport osimport timeasync def makeitem (size: int = 5 )->str : return os.urandom(size).hex () async def randsleep (caller:str = None )->None : i = random.randint(0 , 10 ) if caller: print (f"{caller} sleep for {i} seconds." ) await asyncio.sleep(i) async def produce (name:int , q:asyncio.Queue )->None : n = random.randint(0 , 10 ) for _ in it.repeat(None , n): await randsleep(caller=f"Producer {name} " ) i = await makeitem() t = time.perf_counter() await q.put((i, t)) print (f"Producer {name} add <{i} > to queue." ) async def consume (name:int , q:asyncio.Queue )->None : while True : await randsleep(caller=f"Consumer {name} " ) i,t = await q.get() now = time.perf_counter() print (f"Consumer {name} got element <{i} > in {now - t:0.5 f} seconds) q.task_done() async def main(np:int, nc:int): q = asyncio.Queue() producers = [asyncio.create_task(produce(n, q) for n in range(np))] consumers = [asyncio.create_task(consume(n, q) for n in range(nc))] await asyncio.gather(*produers) await q.join() for c in consumers: c.cancel() def cli(np:int=5, nc:int=10): random.seed(666) start = time.perf_counter() asyncio.run(main(np, nc)) elapsed = time.perf_counter() print(f" Program completed in {elapsed:0.5 f} seconds.") if __name__ == " __main__": import fire fire.Fire(cli)
运行程序,查看结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ python3 asyncq.py --np 2 --nc 5 Producer 0 sleeping for 3 seconds. Producer 1 sleeping for 3 seconds. Consumer 0 sleeping for 4 seconds. Consumer 1 sleeping for 3 seconds. Consumer 2 sleeping for 3 seconds. Consumer 3 sleeping for 5 seconds. Consumer 4 sleeping for 4 seconds. Producer 0 added <377b1e8f82> to queue. Producer 0 sleeping for 5 seconds. Producer 1 added <413b8802f8> to queue. Consumer 1 got element <377b1e8f82> in 0.00013 seconds. Consumer 1 sleeping for 3 seconds. Consumer 2 got element <413b8802f8> in 0.00009 seconds. Consumer 2 sleeping for 4 seconds. Producer 0 added <06c055b3ab> to queue. Producer 0 sleeping for 1 seconds. Consumer 0 got element <06c055b3ab> in 0.00021 seconds. Consumer 0 sleeping for 4 seconds. Producer 0 added <17a8613276> to queue. Consumer 4 got element <17a8613276> in 0.00022 seconds. Consumer 4 sleeping for 5 seconds. Program completed in 9.00954 seconds.
可以尝试更改消费者和生产者的数目然后查看程序最终的运行时间,随着生产者和消费者数目的增加,程序的执行时间却没有太大的变化。影响这个程序运行时间的原因有两个:
无可避免的程度执行耗时即每条语句以及协程切换的时间
当所有的消费者都在sleep的时候队列中放入了数据,导致数据无法处理
需要注意的是,在这个程序中可以一直增加消费者和生产者的数量,但是当生产者和消费者达到一定数目后,PC的CPU性能就变成了限制程序速度的主要因素,程序的执行速度变慢。
首先看一个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import asyncio@asyncio.coroutine def py34_coro (): """Generator-based coroutine""" s = yield from stuff() return s async def py35_coro (): """Native coroutine, modern syntax""" s = await stuff() return s async def stuff (): return 0x10 , 0x20 , 0x30
分别直接运行 py34_coro()和py35_coro(),查看输出
1 2 3 4 5 In [5 ]: py35_coro() Out[5 ]: <coroutine object py35_coro at 0x7fa84498c830 > In [6 ]: py34_coro() Out[6 ]: <generator object py34_coro at 0x7fa844933050 >
直接运行函数并没有得到期望的结果,而是得到了一个对象,可以分别称为生成器对象和协程对象。
再来一个生成器的例子
1 2 3 4 5 6 7 8 >>> def gen ():... yield 0x10 , 0x20 , 0x30 ... >>> g = gen()>>> g <generator object gen at 0x1012705e8 > >>> next (g)(16 , 32 , 48 )
当调用生成器函数的时候会返回一个对象,如果想要得到函数的返回值则需要使用next函数来获取。异步函数也是类似的实现思路,直接调用函数会得到一个对象,如果想要得到函数的返回值就需要使用asyncio.run()等函数来获取。
还有一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 >>> from itertools import cycle>>> def endless ():... """Yields 9, 8, 7, 6, 9, 8, 7, 6, ... forever""" ... yield from cycle((9 , 8 , 7 , 6 ))>>> e = endless()>>> total = 0 >>> for i in e:... if total < 30 :... print (i, end=" " )... total += i... else :... print ()... ... break 9 8 7 6 9 8 7 6 9 8 7 6 9 8 >>> >>> next (e), next (e), next (e)(6 , 9 , 8 )
生成器可以快速的停止和重启(停止其实是挂起,所有的状态都保存了),协程工作方式类似,可以做到快速挂起,然后让出控制权。
生成器还有一个鲜为人知的特点,在调用生成器对象的时候可以使用send函数来传递一些信息,例如:
1 2 3 4 5 6 7 8 def consumer (): r = '' while True : n = yield r if not n: return print ('[CONSUMER] Consuming %s...' % n) r = '200 OK'
可以这么调用它
1 2 3 4 5 >>> c = consumer()>>> c.send(None )>>> c.send(12 )[CONSUMER] 12 ... '200 OK'
总结一下上面所说的东西
协程实际上就是一个特别的生成器
老版本的python使用yield form关键字,而新版本的使用await代替,这两种关键字的作用是相同的,但是await可以帮助我盟更好的理解程序
程序会在await处让出控制权,然后继续执行,直到执行的程序返回
一个异步生成器的例子:
1 2 3 4 5 6 7 >>> async def mygen (u: int = 10 ):... """Yield powers of 2.""" ... i = 0 ... while i < u:... yield 2 ** i... i += 1 ... await asyncio.sleep(0.1 )
可以按照如下的方式调用它
1 2 3 4 5 6 7 8 9 10 11 12 >>> async def main ():... ... ... g = [i async for i in mygen()]... f = [j async for j in mygen() if not (j // 3 % 5 )]... return g, f... >>> g, f = asyncio.run(main())>>> g[1 , 2 , 4 , 8 , 16 , 32 , 64 , 128 , 256 , 512 ] >>> f[1 , 2 , 16 , 32 , 256 , 512 ]
异步生成器与其他异步程序的区别是:异步生成器并没有将整个循环过程变成并发的过程,即即使使用了异步生成器,它的执行速度还是和普通的生成器没有区别。异步生成器只是表示可以将控制权转移。
异步的实现方式可以看作为一个事件循环,即有一个循环程序在不停的询问每一个协程是否可以将控制权转让以及是否再次需要控制权,在得到协程的响应之后将控制权进行相应的转移。
对于3.7及以上版本的python而言,启动时间循环,然后运行协程可以通过一句命令完成
如果你不限麻烦的话可以调用其他的API
1 2 3 4 5 6 7 8 loop = asyncio.get_event_loop() try : loop.run_until_complete(main()) finally : loop.close()
如果你不需要修改协程的运行方式,第一种方式会更加合适一些。
单个协程并不能节省程序的运行时间
所有的协程默认都运行在单个线程内,这意味着大量的协程会造成程序运行速度的显著降低,当然也可以在多个核心上面运行所有协程。参考这个网址
https://youtu.be/0kXaLh8Fz3k?t=10m30s
在介绍了异步io的使用方式之后,下面是一个使用异步io的完整示例
读入一个内容为一系列url的文本文件
使用resuests或类似的库获取网页信息并解析,如果url无效则停止处理
搜索网页内容里面的超链接
把搜索到的内容写入一个文本文件
使用异步方式完成上述操作
异步网络访问需要使用aiohttp库来作为web请求的库。这里会有一个问题,为什么不使用requests库来进行web请求?requests库的函数调用都是阻塞状态的,如果直接拿来在异步程序中使用起不到协程的作用,因为阻塞的requests函数调用是不可等待的。一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import timeimport asyncioasync def request (caller=None ): for i in range (3 ): time.sleep(1 ) print (f"{caller} :{i} " ) async def test (name ): await request(name) async def main (): await asyncio.gather(*(test(i) for i in range (3 ))) if __name__ == "__main__" : import time s = time.perf_counter() asyncio.run(main()) cost = time.perf_counter() - s print ("%s run cost %0.5f s" %(__file__, cost))
运行程序
1 2 3 4 5 6 7 8 9 10 11 $ python async_call_sync.py 0 :0 0 :1 0 :2 1 :0 1 :1 1 :2 2 :0 2 :1 2 :2 ./test.py run cost 9.01359 s
如果将上面的程序修改一下:
1 2 3 4 async def request (caller=None ): for i in range (3 ): await asyncio.sleep(1 ) print (f"{caller} :{i} " )
再次运行
1 2 3 4 5 6 7 8 9 10 11 $ python async_call_sync.py 0 :0 1 :0 2 :0 0 :1 1 :1 2 :1 0 :2 1 :2 2 :2 ./test.py run cost 3.00469 s
如果你真的很想使用requests库,那么可以参照这个文章修改:
https://docs.python.org/3/library/asyncio-eventloop.html#executing-code-in-thread-or-process-pools
https://stackoverflow.com/questions/43241221/how-can-i-wrap-a-synchronous-function-in-an-async-coroutine
https://zhuanlan.zhihu.com/p/56927974
或者使用这个库 https://github.com/oremanj/greenback
url文件内容,这些url大部分都是国外的网站,如果打不开可以用国内网站替换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ cat urls.txt https://regex101.com/ https://docs.python.org/3 /this-url-will-404. html https://www.nytimes.com/guides/ https://www.mediamatters.org/ https://1.1 .1 .1 / https://www.politico.com/tipsheets/morning-money https://www.bloomberg.com/markets/economics https://www.ietf.org/rfc/rfc2616.txt $ cat urls_cn.txt https://regex101.com/ https://1.1 .1 .1 / https://www.163 .com https://www.qq.com https://www.baidu.com https://www.sina.com
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import asyncioimport loggingimport reimport sysfrom typing import IOimport urllib.errorimport urllib.parseimport aiofilesimport aiohttpfrom aiohttp import ClientSessionlogging.basicConfig( format ="%(asctime)s %(levelname)s: %(name)s:%(message)s" , level=logging.DEBUG, datefmt="%H-%M-%S" , stream=sys.stderr, ) logger = logging.getLogger("areq" ) logging.getLogger("charder.charsetprober" ).disabled = True HREF_RE = re.compile (r'href="(.*?)"' ) async def fetch_html (url:str , session:ClientSession, **kwargs )->str : resp = await session.request(method="GET" , url=url, **kwargs) resp.raise_for_status() logger.info("Got response [%s] for URL:%s" , resp.status, url) html = await resp.text() return html async def parse (url:str , session:ClientSession, **kwargs )->set : found = set () try : html = await fetch_html(url=url,session=session, **kwargs) except ( aiohttp.ClientError, aiohttp.http_exceptions.HttpProcessingError, ) as e: logger.error( "aiohttp exception for %s [%s]: %s" , url, getattr (e, "status" , None ), getattr (e, "message" , None ) ) return found except Exception as e: logger.exception( "Non-aiohttp exception occured: %s" , getattr (e, "__dict__" , {}) ) return found else : for link in HREF_RE.findall(html): try : abslink=urllib.parse.urljoin(url, link) except (urllib.error.URLError, ValueError): logger.exception("Error parseing URL: %s" , link) pass else : found.add(abslink) logger.info("Fond %d links for %s" , len (found), url) return found async def write_one (file:IO, url:str , **kwargs )->None : res = await parse(url=url, **kwargs) if not res: return None async with aiofiles.open (file, "a" ) as f: for p in res: await f.write(f"{url} \t{p} \n" ) logger.info("Wrote res for source Url: %s" , url) async def bulk_crawl_and_write (file:IO, urls:set , **kwargs )->None : async with ClientSession() as session: tasks = [] for url in urls: tasks.append( write_one(file=file, url=url, session=session, **kwargs) ) await asyncio.gather(*tasks) if __name__ == "__main__" : import pathlib import sys header = {"User-Agent" :"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.20 Safari/537.36 Edg/97.0.1072.21" } assert sys.version_info >= (3 ,7 ) here = pathlib.Path(__file__).parent with open (here.joinpath("urls.txt" )) as infile: urls = set (map (str .strip, infile)) outpath = here.joinpath("foundurls.txt" ) with open (outpath, "w" ) as outfile: outfile.write("source_uirl\tparsed_url\n" ) asyncio.run(bulk_crawl_and_write(file=outpath, urls=urls, headers=header))
运行程序查看结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 $ python areq.py 14 -01-24 DEBUG: asyncio:Using selector: EpollSelector14 -01-24 ERROR: areq:aiohttp exception for https://1.1 .1 .1 / [None ]: None 14 -01-24 INFO: areq:Got response [200 ] for URL:https://www.baidu.com14 -01-24 INFO: areq:Got response [200 ] for URL:https://www.sina.com14 -01-24 DEBUG: chardet.charsetprober:utf-8 confidence = 0.99 14 -01-24 DEBUG: chardet.charsetprober:SHIFT_JIS Japanese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:EUC-JP Japanese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:GB2312 Chinese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:EUC-KR Korean confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:CP949 Korean confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:Big5 Chinese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:EUC-TW Taiwan confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:windows-1251 Russian confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:KOI8-R Russian confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:ISO-8859 -5 Russian confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:MacCyrillic Russian confidence = 0.010057786647123132 14 -01-24 DEBUG: chardet.charsetprober:IBM866 Russian confidence = 0.07572707827332002 14 -01-24 DEBUG: chardet.charsetprober:IBM855 Russian confidence = 0.038816770341240835 14 -01-24 DEBUG: chardet.charsetprober:ISO-8859 -7 Greek confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:windows-1253 Greek confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:ISO-8859 -5 Bulgairan confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:windows-1251 Bulgarian confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:TIS-620 Thai confidence = 0.041924869728195514 14 -01-24 DEBUG: chardet.charsetprober:ISO-8859 -9 Turkish confidence = 0.5002036123642747 14 -01-24 DEBUG: chardet.charsetprober:windows-1255 Hebrew confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:windows-1255 Hebrew confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:windows-1255 Hebrew confidence = 0.0 14 -01-24 DEBUG: chardet.charsetprober:utf-8 confidence = 0.99 14 -01-24 DEBUG: chardet.charsetprober:SHIFT_JIS Japanese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:EUC-JP Japanese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:GB2312 Chinese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:EUC-KR Korean confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:CP949 Korean confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:Big5 Chinese confidence = 0.01 14 -01-24 DEBUG: chardet.charsetprober:EUC-TW Taiwan confidence = 0.01 14 -01-24 INFO: areq:Fond 6 links for https://www.sina.com14 -01-24 INFO: areq:Got response [200 ] for URL:https://www.163 .com14 -01-24 INFO: areq:Wrote res for source Url: https://www.sina.com14 -01-25 INFO: areq:Fond 45 links for https://www.baidu.com14 -01-25 INFO: areq:Wrote res for source Url: https://www.baidu.com14 -01-25 INFO: areq:Fond 1179 links for https://www.163 .com14 -01-25 INFO: areq:Wrote res for source Url: https://www.163 .com14 -01-25 INFO: areq:Got response [200 ] for URL:https://regex101.com/14 -01-25 INFO: areq:Fond 40 links for https://regex101.com/14 -01-25 INFO: areq:Wrote res for source Url: https://regex101.com/$ head foundurls.txt -n3 source_uirl parsed_url https://www.sina.com http://www.sina.com.cn/intro/copyright.shtml https://www.sina.com https://weibo.com/sinaus?ssl_rnd=1609344845.1816 &is_all=1 $ wc -l foundurls.txt 1271 foundurls.txt
💡 需要注意的是,使用网络访问程序的时候,不要对同一个网站发起过多与过于频繁的请求。这样不仅会增加网站的负担,程序也会因为timeout错误得不到数据。如果有一些网站一直得不到返回数据,可以尝试在请求的时候添加headers参数。
在以上的内容对异步IO介绍了那么多后,相信你一定对异步IO的使用场景有一定的了解。一般来说IO密集的任务都可以使用异步IO,因为此时CPU大部分时间都在等待IO的返回结果:
网络IO,服务端或者客户端
无服务情况,P2P或者多人网络聊天室
不想在使用多线程加锁保护数据进行数据读写的情况
不仅asyncio.gather可以创建协程,create_task也可以,例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 >>> import asyncio>>> async def coro (seq ) -> list :... """'IO' wait time is proportional to the max element.""" ... await asyncio.sleep(max (seq))... return list (reversed (seq))... >>> async def main ():... ... ... t = asyncio.create_task(coro([3 , 2 , 1 ])) ... await t ... print (f't: type {type (t)} ' )... print (f't done: {t.done()} ' )... >>> t = asyncio.run(main())t: type <class '_asyncio.Task' > t done: True
在main函数中必须使用await来等待t的完成,因为在使用asyncio.run的时候会调用函数[loop.run_until_complete(main())](https://github.com/python/cpython/blob/7e18deef652a9d413d5dbd19d61073ba7eb5460e/Lib/asyncio/runners.py#L43) 所有整个时间循环只会关心main这个协程是否已经完成,其他的协程在完成之前就会被取消 ,如果你想得到目前所有在等待的协程可以使用 asyncio.Task.all_tasks()这个函数查看。
对于gather()函数,它的作用只是将所有的协程(futures)放入到一个协程(futures)中,如果使用await开等待gather()函数的协程,就是在等待所有放入gather的协程。并且gather()函数还可以获得协程的返回结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> import time>>> async def main ():... t = asyncio.create_task(coro([3 , 2 , 1 ]))... t2 = asyncio.create_task(coro([10 , 5 , 0 ])) ... print ('Start:' , time.strftime('%X' ))... a = await asyncio.gather(t, t2)... print ('End:' , time.strftime('%X' )) ... print (f'Both tasks done: {all ((t.done(), t2.done()))} ' )... return a... >>> a = asyncio.run(main())Start: 16 :20 :11 End: 16 :20 :21 Both tasks done: True >>> a[[1 , 2 , 3 ], [0 , 5 , 10 ]]
gather()函数只有当所有放入的协程都完成之后才会返回,如果想单独返回已经完成的协程值,可以这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> async def main ():... t = asyncio.create_task(coro([3 , 2 , 1 ]))... t2 = asyncio.create_task(coro([10 , 5 , 0 ]))... print ('Start:' , time.strftime('%X' ))... for res in asyncio.as_completed((t, t2)):... compl = await res... print (f'res: {compl} completed at {time.strftime("%X" )} ' )... print ('End:' , time.strftime('%X' ))... print (f'Both tasks done: {all ((t.done(), t2.done()))} ' )... >>> a = asyncio.run(main())Start: 09:49 :07 res: [1 , 2 , 3 ] completed at 09:49 :10 res: [0 , 5 , 10 ] completed at 09:49 :17 End: 09:49 :17 Both tasks done: True
更多await的使用方法可以参考这个:examples of await expressions from PEP 492.
asyncio - Asynchronous I/O - Python 3.10.1 documentation
Async IO in Python: A Complete Walkthrough - Real Python
协程